It’s been a while since I last posted, and I sort-of feel I should get back into the habit again. Honestly, I think I should also post a few relaxed things instead of waiting for epic posts to consider. I feel that I take too long to finalise things and when done just move onto the next project without doing anything about it. So, today, to share what I’ve been working around – I was on the hunt for a newer, improved, local code agent I could use.
I was looking for a newer trained model than my previous decent models, such as Claude Opus 4.6. So, with the decent open models at larger sizes, I had a little trouble with my slightly limited local hardware. After trying several models over the last few weeks, I decided on the unsloth GGUF of Qwen3.6 A3B at the small IQ3_XSS size.
With a dirt simple testing prompt ignoring proper logical prompt engineering:
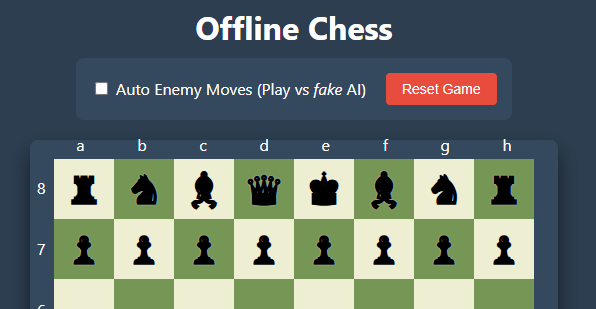
can you make chess in html/js with it showing the board co-ordinates and you start as white player with the moves being ensured are correct; do not use any external scripts, and allow a tickbox for game mode for ‘auto enemy moves’ so 2 players can play against on another if they want to
Prompt
We get the following game (may not work as intended on mobile):
Generally speaking, at first, it was better than I expected. With only small adjustments to some CSS for the layout and ensuring you know the AI player has nothing to do with AI at all, an acceptable result. Generally speaking, it needs a fix for some check mate checks and conditions (cough, yes, a checkmate at times allows the king to take a piece that is protected). So, I did my own small logic fixes and improvements, and voila! Chess versus (not) AI with pure HTML, JS, and CSS. Yeah, online here on my site, offline with just the file on my machine.
The thought of the day, would one consider this a good enough testing question for the model to ensure it can code?
I’d dare say that with all the scoreboards these days, people are glued to showing models getting better “higher scores,” I’m usually disappointed. Great, they were trained on the right data for those questions, but many of the highest scoring models give me completely incorrect answers to project related code questions. Especially as they have the history of all messages I ever sent them.
There are other outliers with troubles. For instance, a popular model shown creating a game from scratch I noticed used React. Not bad for proving it could create a game; I asked to see if we could diversify it, and asked it to instead use pygame, which many models I’ve tried can do without any issue. The result: a differently scripted React game. Gave up and told it again, ‘no, in python‘ blatantly and got a 3rd React solution.
The gif is super low quality, but you get the idea:


Yeah, I felt like exploring what I did more regularly in the past as a hobby. You may, or may not, see me release a new game in the future. Though, I won’t put any dates on it yet, it’s a mind calming activity for me to make my own games again.

